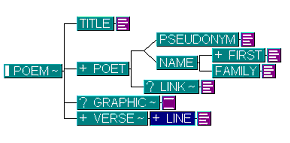
Graphical representation of the elements in Poem.dtd
ABSTRACT: The purpose of the paper is to document experiences of using XSLT and DOM in document transformations. The case environment in the experiments is a fictional company, Poem Publishers, Inc., which publishes Finnish poems on the Web. The paper describes the publishing process, which requires several different schemas for editing, archiving and presentation purposes even for such simple publications as poems. Technical environment is based on Microsoft Tools such as IIS 5.0 Internet Server, MSXML 3.0 parser, ASP 3.0 technology and Internet Explorer 5.5. The paper discusses also discovered problems related to rapidly evolving software products, difficulties with semi-manual parser installation and problems with character encodings and external entities in transformations.
XML (eXtensible Markup Language) together with supporting technologies, such as CSS (Cascading Style Sheets) or XSL (eXtensible Stylesheet Language) for adding layout, and XSLT (XSL Transformations) and DOM (Document Object Model) for document transformations, forms a foundation for general multichannel document publishing both on paper and on the Web. In this paper we discuss experiences of a case study, in which the Microsoft technologies and tools [MI01] were used for experimental publishing of poems. Although the technologies seemed to do well for many of the tasks they were needed, it was found in the study that there are still some problems, which hamper the publishing process. The problems were largely due to the immaturity of the tools, for example, the limited level of support for the standards in the tools caused sometimes problems, which forced us to use non-standard solutions.
In the following Section we describe Poem Publishers, Inc., and the structure of the poems it publishes. The publishing environment of the company is further explained on Section 3, while in Section 4 we take a look at the transformations in general, and especially in Poem Publishers, Inc. Experiences and problems found during the case study are discussed in Section 5. Finally, in Section 6 we summarize the lessons we learned during the implementation of the publishing system.
Poem Publishers, Inc. is a fictional company, whose mission is to publish Finnish poems on WWW (World-Wide Web). The company publishes poems authored by several poets, only requirement is that the form of the poems must be traditional, i.e. no fancy layouts are allowed.
The poets are free to use whatever text-processing tool they want while writing their poems. However, Poem Publishers, Inc. recommends some XML editor to be used, because that way the quality of the XML format can be ensured. In order to ensure a smooth publishing process, the Poem Publishers, Inc. has developed an XML DTD (Document Type Definition) of its own, which all the poets should use at least when sending their poems to the company. If they choose to use the same DTD in their authoring the poets can use the authoring environment offered by Poem Publishers, Inc., which is especially designed for XML editor called XMetaL [SQ01]. In the DTD of the Poem Publishers, Inc. there are elements for the title of the poem, name or pseudonym of the poet, link to the poets homepage, and possible graphic. Attributes of the link element are from XLink namespace. The poem itself should consist of one or more verses consisting one or more lines each. The verses can be repeatable if so indicated by an attribute. For now there are three kinds of poems: classic, children's poem, or other. fig01 shows the elements of the Poem.dtd in a graphical form by created by Near & Far Designer 3.0 [OT01].
Graphical representation of the elements in Poem.dtd
When there are enough poems of any of the types in Poem Publishers, Inc. a book of poems is assembled. For the poem collection a DTD called poemcoll.dtd has been designed. On WWW, however, the poems can be published as soon as they arrive. The name of each poem appears in a poem list, which serves as a link to the poems. With each poem a banner advertising Poem Publishers, Inc. is shown to the readers. The information in the banner is organized according to a separate DTD (pubinfo.dtd) for publisher information.
The publishing environment in the Poem Publishers, Inc. includes a Microsoft IIS server v. 5.0, which supports Jscript and VBscript as they are used in ASP 3.0 (Active Server Pages). IIS server also enables the use of DOM II interface. The electronically published poems were mostly browsed by Internet Explorer 5.5 browser, because it supports quite well the CSS style language on level 2. CSS itself was chosen as a language for adding layout to the poem because during the development of the publishing environment of Poem Publishers, Inc. XSL was not considered mature enough since it had not gained a status of W3C (World-Wide Web Consortium) recommendation. However, for making document transformations with XSLT language or with DOM II objects and interfaces on the browser, a newer version of Microsoft XML parser called MSXML 3.0 has to be installed into the browser.
At this point the Poem Publishers, Inc. did not see any reasons for investing money to buy any database for the poems. Instead, the poems are stored as separate files, after they have been sent to the publisher by the poets. In the future, however, when the amount of poems increases, it may be a good idea to consider acquiring a database for them.
A document can be transformed either manually or by using a program. A simple transformation can be done by using the find-replace function in text editor. When there are many documents to transform, or when the transformation is more complex, you can use transformation languages and/or programs based on them for the task. There are two basic techniques used for SGML (Standard Generalized Markup Language) and XML transformations [LI97]; [ME01]): event-based mapping and tree-based mapping. In event-based transformation a parser does not construct a parse tree, but reads the source document in serial order and outputs information of any elements found, or responds via API (Application Programming Interface) to the requests related to the events the parser encounters (of which one is an element occurrence). When using the tree-based mapping formalism a parser constructs a parse tree of the source document, and a transformation program can 'navigate' on source document structure, simultaneously defining transformations or filtering content from the source document to the output document. A parse tree offers us the means to perform more complex transformations and filtering because with it we have a better control over the output of a transformation [LI97].
TABLE 1 presents an overview of differences between event-based and tree-based transformations (discussed by [LI97]; [ME01]).
| Event-based mapping technique | Tree-based mapping technique | |
|---|---|---|
| Examples of languages |
|
|
| Pros/cons. |
|
|
Nowadays it seems that both the XSLT language and SAX (Simple API for XML) and DOM interfaces are becoming popular and are frequently used. When using SGML, the transformation languages such as DSSSL (Document Style Semantics and Specification Language) OMNIMARK®, or BALISE® were mastered by a small number of people specialized to transformations. Now XML has gained wider acceptance and there are cheap or free tools for document transformations available. When using transformation techniques the speed is not the only issue. If you already use some technique it is not reasonable to mix all the other approaches into your process. For example, if you use XSLT because some of your transformations are complex, it might be good idea to use it in other transformations as well in order to make it easier to update them.
There are at least three different ways for performing a transformation of XML file with XSLT and DOM either on a browser/client or in a server:
In the source XML file there is a link to XSLT file. The transformation is processed in browser/client.
The source XML file and source XSLT file are loaded as DOM objects and transformation is performed using DOM transformNode or transformNodeToObject method. This can be done in two ways: with .html file processed in browser or with .asp file processed in server.
The source XML is loaded as DOM object and the transformation is being done by using DOM interface methods and properties (using Java or ECMAscript, or Jscript or Javascript versions of ECMAscript) from programming/scripting language in a .html file processed in browser.
In the transformation it is possible to add a link to other XSLT file or to CSS style sheet in the transformation output document. Therefore, the output document can be rendered with CSS in browser when the document is shown to the user. The output document can also be transformed again. At the moment with XSLT you can output text, HTML (HyperText Markup Language) or XML. If your output is XML, you can then write your output according to numerous XML applications/vocabularies available; such as WML (Wireless Markup Language) or XHTML (eXtensible HyperText Markup Language)
If the whole transformation chain is performed in a browser, with ordinary tools there is no way to see the results of the second phase of the chain (the output of the XSLT transformation including a link to a CSS file). Microsoft provides a handy tool for assistance in these kind of situations called as "Internet Explorer Tools for Validating XML and Viewing XSLT output". With this tool, you can see the output resulting from XSLT transformation on a client (Internet Explorer browser).
The idea of chaining the transformations can be developed even further by using reusable COM (Component Object Model) components and ASP pages as transactions. In the publishing process we discovered that it is not necessary to copy frequently used piece of a transformation template to all places where they are needed. Instead, the frequently used template could be saved as a document of its own and used then in chain with some other transformation documents. In some cases it is also possible to call other transformation files from a 'main' transformation document.
We tested three kinds of transformations in publishing the poems:
XML-to-XML
XML-to-HTML
XML-to-XHTML
XML-to-XML transformation was required in order to transform the poems confirming the 'author's DTD' to more suitable format for publishing. In this transformation we also added fixed attribute values to the documents, because the XML editor had left them out of the XML file. The last two transformations were needed to enable the poems to be rendered for the browser. We decided to use XSLT in the actual transformations, and DOM mainly as a way to load source and transformation documents (i.e. from the transformation procedures listed in Section 4.2 we used mainly 2, but also 1).
Despite the transformation from XML formatted file confirming to author's DTD to XML format confirming to the publishing DTD, all transformations included a link to the CSS definition to be added into the output file. The transformation chain therefore can be defined like in fig02.
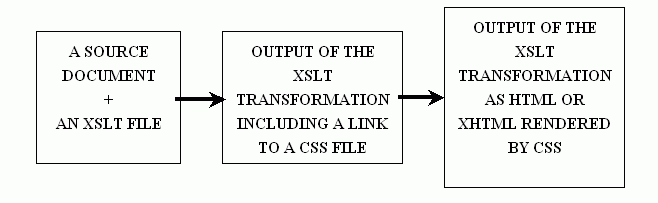
Transformation chain
We tested the transformation chain so that it was either performed totally in client's side in a browser, or the first two phases were performed in a server. In the second option the server sends the output of the XSLT transformation to the client and the browser renders the document according to the CSS rules.
An example of chaining the transformation and using reusable components is the inclusion of the information of Poem Publishers, Inc. within each of the poems as a header or footer, when rendering them on Web. The information about the publisher resides in its own XML document. When the information is needed in the header or footer of the final output documents, they can be accessed via a variable element of XSL language in transformation document. However, the information should be transformed to confirm the language used in other parts of the output document (i.e. HTML or XHTML). Therefore the XSLT transformation, which does the XML-to-HTML or XML-to-XHTML transformation should be saved as a transformation document of its own. Now you can either build a chain of transformations in a server's transaction function, or call the needed transformation document from within the original transformation document, which transforms the XML formatted poem into desired output format.
To be able to use XSLT language and DOM II one needs to use MSXML 3.0 parser. The parser that comes with Internet Explorer 5, 5.5 (and presumably the one within IE6) is either MSXML 2.5 or MSXML 2.6. MSXML 2.X-parsers do not support XSLT W3C recommendation, instead they support a dialect called as XSL Patterns. This is Microsoft's own interpretation with enhancements of the W3C XSLT draft that was available at the time MSXML 2.X parser's XSLT processor was designed and prepared. In practice, a Microsoft parser is a COM-component, that is installed in user's Windows NT/Windows32 folders as MSXMLx.dll. Internet Explorer then uses this component for parsing XML documents (for showing XML on browser screen) and for carrying out XSLT transformations by using the parser's built-in XSLT processor.
The MSXML 3.0 parser installation is rather complicated. For installation one needs to have a windows installer program (InstMsi), MSXML parser files, and a regsvr32 program for registering the MSXML 3.0 parser into system registry instead of an old parser. One also has to know whether the MSXML 3.0 parser should be installed in Replace or in Side-by-side mode.
Sometimes people are confused because they really cannot see whether the parser is installed and registered appropriately. If one studies the XSLT- FAQ (Frequently Asked Question )'s (such as in http://www.netcrucible.com) or follows the discussion on XSLT lists (such as for example a XSL list provided by Mulberry Technologies, see http://www.mulberrytech.com/xsl/xsl-list/index.html) one can see that the question of the use of wrong MSXML parser version or detecting which parser is actually used by Internet Explorer comes up constantly. After one solves these installation problems the use of MSXML 3.0 parser and additional tools provided by Microsoft works quite well — except if one needs to take special care of character encodings. This is not to say that Microsoft tools are "the best" or "not good" — we can only discuss of the tools we have used. If one is interested in other parsers and XSLT processors one can find multiple other shareware programs (see: for example a list of tools in XML Cover Pages in http://xml.coverpages.org/publicSW.html). For those who are interested there is also available a comparison tool for XSLT processors. It can be found in Netcrucible community (http://www.netcrucible.com/XSLT/XSLT-tool.htm).
When we use an XSLT transformation to, for example, output HTML from XML source document, the special characters (represented by entities) in our source document are being re-encoded into the appropriate output-encoding characters, if not specially escaped in the transformation. For example, in Poem Publishers, Inc. we had many minor technical problems with character encodings. We wrote our style sheets and document manipulation scripts with NoteTab editor, using iso-8859-1 encoding. The internal character encoding MSXML 3.0 uses is UTF-16. If a document that is transformed is manipulated as a string, the output document is also encoded as UTF-16 string. If the input document is manipulated as a DOM object, for example, the input and output documents are safely encoded with the same (we used iso-8859-1) encoding. One problem was, that whether the encoding was changed during the transformation or not, the MSXML 3.0 parser outputted 'encoding ="UTF-16"' to the transformation output documents as an pre-defined value. This might cause problems when trying to reprocess or view these documents.
The browser itself does not automatically understand that certain elements in the DTD should be rendered as links. This is quite natural, because in every DTD the element representing something that should be connected to some other resource can be named according to DTD designer's own preferences. A solution for representing the desired element as a link in a browser is to use a namespace declaration of either HTML 4.0 or XHTML in either the DTD or document instance. It should be noted, however, that browsers provided by different vendors do have dissimilarities in rendering XML documents or understanding namespace declarations.
For the poet's point of view, however, the namespace declarations in the DTD might seem confusing. Therefore we decided to write a more content oriented DTD for the authoring phase without any references to HTML or XHTML. The poets produced with this 'author's DTD' are then transformed via XSLT to XHTML while the poems are published.
The publishing process in Poem Publishers, Inc. places multiple requirements for the implementers. Even if XML itself is independent of the operating system, the environment where the documents are processed, and the programming languages affect the publishing process and its management. Along with XML, the person(s) responsible for the process should be familiar with transformation interface definitions (SAX or DOM) or XSLT, and at least to some extend also some programming or scripting language used in a server of with transformation interface definitions (Java, ECMAscript/JavaScript, Jscript, etc.). Also knowledge about ASP technology was needed.
In organization in general, there is not necessarily any single person, who were an expert on all the above-mentioned areas. Therefore, co-operation of key persons from publishing environment experts as well as XML and transformation technique experts is necessary. Also, it would be recommendable to limit the programming and scripting languages to minimum within a publishing environment in order to make updating the applications easier.
The work with Poem Publishers, Inc. was a valuable learning experience for us. It has been a good way to demonstrate in practise the problems and solutions encountered in electronic publishing in contemporary world.
When processing the documents same character encodings should be used in the source documents and the transformation scripts. When publishing the XML formatted documents on the Web, it is almost mandatory to transform the documents into either HTML or XHTML formats, because the browsers have no knowledge about the meaning of each individual element.
It is recommendable to let the structure of the source XML document be as content oriented as possible. The transformations to less detailed HTML or XHTML formats can be done with transformation techniques like XSLT or DOM. Usually it is also useful to have multiple versions of the structure definitions (DTDs), because the content providers or editing software may have some requirements of their own, while the processing of the document in publishing process might have different of even contradictionary demands.
The support level of different browsers varies considering CSS, XSLT, and XML itself. Some browsers support HTML the best (or exclusively), but in the future the support for XHTML will become wider. Especially terminals with slow connections will prefer XHTML over HTML. Therefore, different kinds of transformation are more and more needed.
In general, it would seem like there were tools available with a adequate quality for building XML publishing environments. However, the implementers should be aware of possible extra time needed for dealing with character encodings, scripting languages, installing parsers, and dealing with different versions of building blocks of the publishing environment.
LI 1997: Lindén, Greger, 1997. Structured document transformations (PhD Thesis, Series of Publications A, Report A-1997-2). Helsinki: Department of Computer Science, University of Helsinki.
ME 2001: Megginson, David, 2001. SAX: Simple API for XML. Available: http://www.megginson.com/SAX/index.html [2001, March, 15].
MI 2001: Microsoft, 2001. MSDN Library: XML http://msdn.microsoft.com/library/default.asp?url=/nhp/Default.asp?contentid=28000438. MSDN Downloads: Web Development/XML http://msdn.microsoft.com/downloads/default.asp
OT 2001: OpenText, 2001. The industrial strength XML modeling and authoring tool. OpenText corporation. Available: http://www.opentext.com/near_and_far/ [2001, October, 2].
SQ 2001: SoftQuad, 2001. SoftQuad XMetaL. Available: http://www.softquad.com/top_frame.sq?page=products/xmetal/content_xmetal.html [2001, October, 1].
— M.SC (econ.) Anne Honkaranta has been working and doing research with structured documents since 1995. She mainly has focused on the management or technical, structured documentations and learning/distance learning materials. Her M.Sc thesis was about defining a content-oriented structure model for distance learning materials. At the moment she is working with her PhD thesis. The doctoral research is focused on the information content reuse in the management of structured documents. As a case of content reuse she has been studying the possibilities of information content reuse between Operation & Maintenance Manuals and Education & Training materials in an industrial organization for a couple of years. Her best friend and main hobby is her short-coated, 11-years old Chihuahua Donna. Books and movies (specially sci-fi ones), and horse-riding now and then are also Anne's hobbies along with "slow-motion gardening".
— Since 1996, Virpi Lyytikäinen has been doing research related to structured SGML/XML documents at the Department of Computer Science and Information Systems in the University of Jyväskylä. At the moment she works in a project called inSGML, which is developing, testing and customizing methods for the SGML/XML standardization process especially for industrial purposes. The work is related to her Doctoral Thesis, whose subject is methods for SGML standardization. During the years 1998-2000 she worked in a project called EULEGIS, which was developing a unified interface for different legal databases in the Internet. Before that she worked in RASKE project, which developed means and methods for deployment of structured SGML documents in major Finnish public sector organisations. RASKE was a joint project, whose participants included Parliament of Finland, and ministries of the Finnish government.
— Since 1996, Pasi Tiitinen has been doing research related to structured SGML/XML documents at the Department of Computer Science and Information Systems in the University of Jyväskylä. At the moment he works in a project called inSGML, which is developing, testing and customizing methods for the SGML/XML standardization process especially for industrial purposes. The work is related to his Doctoral Thesis, whose subject is usability of structured documents. During the years 1998-2000 he worked in a project called EULEGIS, which was developing a unified interface for different legal databases in the Internet. Before that he worked in RASKE project, which developed means and methods for deployment of structured SGML documents in major Finnish public sector organisations. RASKE was a joint project, whose participants included Parliament of Finland, and ministries of the Finnish government.