Publishing process of Poem Publishers, Inc. - overview
ABSTRACT: This tutorial is meant for beginners and those who do not consider themselves as experts on Web publishing using XML on a server. However, basic knowledge of XML helps to understand the presentation.
The purpose of preparing this demonstration was to explore document processing and transformation techniques (XSLT (XSL Transformations) and via DOM (Document Object Model) interface) in Microsoft Internet Information Server 5.0/ ASP (Active Server Pages) 3.0 and Internet Explorer 5.0-6.0 (see [MI01] ) environments. In this demonstration we would like to share some ideas and experiences we gained when working with Poem Publishers, Inc, which we created as an imaginary company for exploratory purposes. In this demonstration we discuss and show examples of: support for XML (eXtensible Markup Language) on browsers and publishing process overview (chapter 1), transformation types that we needed for WWW (World-Wide Web) publication process (chapter 2), how to accomplish transformations on the server-client environment (chapter 3), and finally some experiences considering the tools we used. (chapter 4).
The demonstration of Poem Publishers, Inc. shall also become publicly available during November 2001. There shall be a link to the demonstration and it's documentation in: http://haades.it.jyu.fi/inSGML/
XML language reached the status of W3C recommendation on 1998. On the same year reached the style language for HTML (HyperText Markup Language) and XML documents, CSS (Cascading Style Sheets) level 2, also the status of W3C recommendation. We did a fast check on the XML and CSS support on browsers. At the moment the level of support to CSS2 seems to be rather extensive in the newest versions of all major browsers - Internet Explorer (from version 5.5 and up), Netscape (version 6.0 and up) and Opera (version 5.0 and up). However, that does not - unfortunately - mean that one could publish XML documents as such. In a browser one cannot, for example, see figures that are in the XML document, and even though we can define XLinks in our documents they do not necessarily work. The reason is quite obvious: browser cannot possibly know that for example <kuva> is a start tag for a figure element. Even if your figure (or link) element name is <IMG> (or A, respectively) which is same name that the HTML language uses, the browser does not necessarily know that this XML element needs to be rendered in the same way that it would be rendered if your document was HTML. If you want to, you can define, e.g. when Internet Explorer is used, the image and link elements in your XML documents with same names that HTML uses. Then, you can tell the browser that they should be rendered as HTML <IMG> or <A> elements by using namespace mechanism and by defining these elements in HTML namespace. Then, you would have elements like HTML:IMG and HTML:A in your document. On the other hand, this might be quite confusing for the content provider.
It also seems that the namespace support in different browsers and XML software in common varies. In Poem Publishers, Inc. we came into the conclusion that we produce poems with content oriented, not layout oriented DTD (Document Type Definition) . Then for viewing or publishing the poems we would do document transformations from XML to necessary output/publishing languages and formats.
We also reviewed publishing languages and formats in end-user devices. It seems that the XHTML (eXtensible HyperText Markup Language) language is going to be quite popular. Since XHTML is a reformulation of HTML as XML-based language, XHTML shall be easier to process e.g. by browsers used in portable devices. Therefore we decided that Poem Publishers, Inc. should produce HTML and XHTML versions of poems for end users.
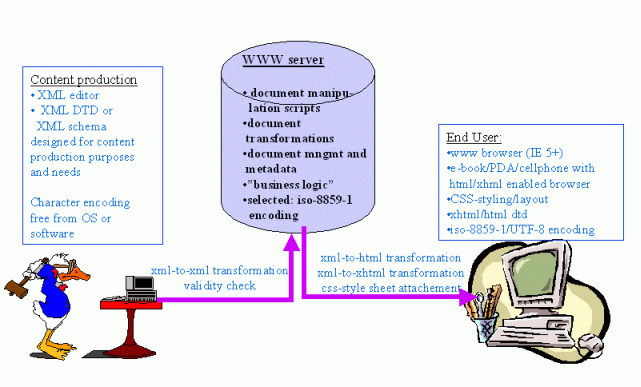
We also considered the needs of editors and content production. Content producers might want to see their poems with some kind of layout formatting. They might also have other requirements for content production, such as a need to define their figures as figure entities when producing the content. We should also make sure that the content production is not dependent of what program one uses or in which environment. Thus, the content-production DTD should use external character encoding tables for ensuring that special marks and letters are coded in portable way. On the other hand, when we process the poems in the server, we do not need figure entity definitions, and we need to use same character encoding throughout all the programs and transformation documents. When the document is transformed, the character entities are outputted in the encoding defined in the transformation unless all the entities are especially escaped. We wrote our XSLT transformations and VBscripts with Notetab editor, which uses iso-8859-1 encoding. So we wanted to use this encoding in the server in all documents, no matter if they were source XML documents, transformation documents or document manipulation scripts on the server. We noticed that it is reasonable to build a three-phase publication process with different aspects covered. The first phase is content production. In this phase we use character encoding tables referred by DTD, and a content-oriented DTD tailored for content production. On the second phase we process the poem documents as iso-8859-1 encoded documents and use no DTD at all. The document content, validity and well-formedness is checked before starting the second phase. On the third phase, we make the necessary document transformations for providing poems defined as HTML or XHTML documents with CSS layout for end users. The publication process and phases are defined in Figure fig01.
Publishing process of Poem Publishers, Inc. - overview
When Poem Publishers, Inc. wanted to publish poems on the WWW, they needed to consider two different aspects of document transformations:
what functionality is needed in publishing, and
what kinds of document transformation techniques are available, and how to choose appropriate technique and tools
There are two basic categories of document transformation techniques: event-based transformations and tree-based transformation. One can also choose whether to use a familiar scripting/programming language (like Java, Jscript, Javascript or VBscript) with programming interfaces,such as SAX (simple API (Application Programming Interface) for XML) or DOM, or XML-based XSLT transformation language. These issues are discussed in, for example [LI97] and [ME01] .
In organization one needs also to consider the maintenance of transformations, and which kinds of programming expertise is needed. Therefore, it might be reasonable to use only one programming/scripting language when using transformation API's and interfaces, and not make every transformation with the optimal technique, API or interface. In Poem Publishers, Inc. we liked to use XSLT language because it seemed to have a quite clear syntax and good control over output document structure. We also thought that later on we could find some benefits on maintenance of transformations, since XSLT language seems to be(come) quite popular, and because XSLT transformation documents are XML documents themselves. We also used DOM interface for loading source and transformation documents and making transformations.
For publication we discovered that we need different kinds of transformations; for example:
XML-to-XML transformations for transforming the poems from "author-fitted structure" and DTD into processing-oriented XML document format/structure (without DTD). (On public demonstration there are examples of XML-to-XML transformations on section 4)
XML-to-HTML and XML-to-XHTML transformations for publishing poems for end-users. (On public demonstration there are several examples of these in sections 2, 3 and 8)
transformations that combine several source documents into one file for making poem collections. (On public demonstration there is an example of combining files into one on section 8)
transformations that combine Poem Publishers, Inc. information with poem content for producing poems with headers or footers. (On public demonstration there are examples of making headers and footers on section 8)
transformations that produce metadata of Poem Publishers, Inc. poems for managing the poems and poem collection production. (On public demonstration there are examples of outputting metadata and producing link indexes on section 8)
We therefore needed also other documents and other DTD's for managing the poem publication. For example, in our demonstration there is an example of writing Poem Publishers, Inc. information in a separate XML file and then adding our company info on the screen as a header of footer when a poem is shown to end-user. Adding a header or footer can be done as document transformation. When we make the XML-to-(X)HTML transformation for preparing the poem for end user, we can also define another transformation which picks up the company info from separate document, transforms it into (X)HTML, and adds the output as a header or footer to the view shown to the end user.
We also defined the poemlist.dtd for writing documents that define poem collections. When we have documents that list the poems and their filenames, we can also write transformations that study each poem file mentioned on the list and output metadata of them (These are discussed on section 8 of the demonstration).
There are at least five different ways for performing a transformation of XML file with XSLT and DOM either on a browser/client or in a server:
In the source XML file there is a link to XSLT file. The transformation is processed in browser/client.
The source XML file and source XSLT file are loaded as DOM objects and transformation is performed using DOM transformNode or transformNodeToObject method. This can be done in two ways: with .html file processed in browser or with asp. file processed in server.
The source XML is loaded as DOM object and the transformation is being done by using DOM interface methods and properties (using Java or ECMAscript, or Jscript or Javascript versions of ECMAscript) from programming/scripting language in a .html file processed in browser.
In the transformation it is possible to add a link to other XSLT file or to CSS style sheet in the transformation output document. Therefore, the output document can be rendered with CSS in browser when the document is shown to the user. The output document can also be transformed again. At the moment with XSLT you can output text, HTML or XML. The transformation chain we used can be defined like in figurefig02.
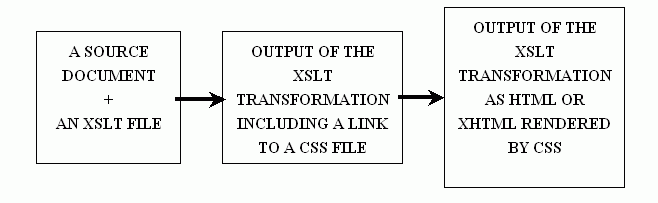
Transformation chain
In WWW server Poem Publishers, Inc. wanted to reuse the transformations and poem files as much as possible. We also considered the XSLT as transformation language more suitable for our needs and coding skills than for example using DOM interface with VBscript or Jscript (which are available in basic Microsoft IIS 5.0 server we used).
Therefore, we would have one .asp (server) page considering each of the main transformation types; one for XML-to-HTML transformation, one for XML-to-XHTML transformation, and one for XML-to-XML transformation. Then, when each of these .asp -pages are asked by the client (IE browser), there would be a query string after the .asp-file name telling the name of the transformation source document. Then, we would have three different ( XSLT) transformation documents, for example xml-to-html.xsl, xml-to-xhtml.xsl and xml-to-xml.xsl, respectively.
For example, if we need to transform Pinkku1.xml to XHTML for browsing, we would send following request: <a href="runo-to-xhtml.asp?Doc=Runot/Pinkku1.xml">View Pinkku1.xml>.(On public demonstration there is an example of sending a query string to server on section 7.)
Two alternative techniques were used for making a transformation:
we used scripting language (such as VBscript) and opened the Pinkku1.xml as text for writing. We then added the link to XSLT transformation document on the Pinkku1.xml source document right after XML declaration.
we used DOM, and created two DOM objects, one for source document and one for transformation document. We then loaded both documents into their DOM objects, made transformation ("transformNode" or "transformNodeToObject"), and sent the resulting document to client. On public demonstration these approaches are illustrated on section 6.
When building up the demonstration, following languages, software and script tools were used:
SoftQuad XMetaL 2.0 document editor for writing and marking up the source documents (poems)(see: www.softquad.com)
Near & Far Designer - for designing DTD's (document type definitions)
Internet Explorer 5.5 browser for viewing XML/ HTML/ XHTML- documents
Internet Information Server 5.0 server program (Microsoft) which uses ASP 3.0 technology and components
Microsoft VBscript scripting language (for using ASP 3.0 classes/components on IIS 5.0 server)
XML language for marking up the source documents
XSLT language version 1.0 and DOM interface from VBscript to make document transformations and prepare documents used for document transformations
Microsoft MSXML 3.0 parser (which includes Microsoft XSLT processor and DOM level I and partly DOM level II interface support)
Microsoft's Tools for Validating XML and viewing XSLT Output (this is an additional helper tool which installs itself "under" the IE5-browser)
During the preparation of Poem Publishers, Inc. we ran into several types of problems. We had difficulties with:
installing the MSXML 3.0 parser
detecting whether the parser is installed or not, and which program-id's or version-dependent id's should we use for calling MSXML 3.0 parser functionality
character encodings: the MSXML 3.0 parser uses UTF-16 as it's internal character encoding. It was difficult to select the appropriate DOM interfaces and ASP methods to use for transformation in order to preserve the selected encoding
We also noticed that even a simple publishing process required many kinds of expertise in the WWW environment. As you can see from the list of tools we used, it is not realistic to expect that one person could master all these programs and programming/scripting/transformation languages well. That means that in the companies one should gather groups of persons mastering different kinds of skills in order to design and create publishing processes - and for maintaining and evaluating them.
LI 1997: Lindén, Greger, 1997. Structured document transformations (PhD Thesis, Series of Publications A, Report A-1997-2). Helsinki: Department of Computer Science, University of Helsinki.
ME 2001: Megginson, David, 2001. SAX: Simple API for XML. Available: http://www.megginson.com/SAX/index.html [2001, March, 15].
MI 2001: Microsoft, 2001. MSDN Library: XML http://msdn.microsoft.com/library/default.asp?url=/nhp/Default.asp?contentid=28000438. MSDN Downloads: Web Development/XML http://msdn.microsoft.com/downloads/default.asp
— M.Sc (econ.) Anne Honkaranta has been working and doing research with structured documents since 1995. She mainly has focused on the management or technical, structured documentations and learning/distance learning materials. Her M.Sc thesis was about defining a content-oriented structure model for distance learning materials. At the moment she is working with her PhD thesis. The doctoral research is focused on the information content reuse in the management of structured documents. As a case of content reuse she has been studying the possibilities of information content reuse between Operation & Maintenance Manuals and Education & Training materials in an industrial organization for a couple of years. Her best friend and main hobby is her short-coated, 11-years old Chihuahua Donna. Books and movies (specially sci-fi ones), and horse-riding now and then are also Anne's hobbies along with "slow-motion gardening".
— Since 1996, Virpi Lyytikäinen has been doing research related to structured SGML/XML documents at the Department of Computer Science and Information Systems in the University of Jyväskylä. At the moment she works in a project called inSGML, which is developing, testing and customizing methods for the SGML/XML standardization process especially for industrial purposes. The work is related to her Doctoral Thesis, whose subject is methods for SGML standardization. During the years 1998-2000 she worked in a project called EULEGIS, which was developing a unified interface for different legal databases in the Internet. Before that she worked in RASKE project, which developed means and methods for deployment of structured SGML documents in major Finnish public sector organisations. RASKE was a joint project, whose participants included Parliament of Finland, and ministries of the Finnish government.
— Since 1996, Pasi Tiitinen has been doing research related to structured SGML/XML documents at the Department of Computer Science and Information Systems in the University of Jyväskylä. At the moment he works in a project called inSGML, which is developing, testing and customizing methods for the SGML/XML standardization process especially for industrial purposes. The work is related to his Doctoral Thesis, whose subject is usability of structured documents. During the years 1998-2000 he worked in a project called EULEGIS, which was developing a unified interface for different legal databases in the Internet. Before that he worked in RASKE project, which developed means and methods for deployment of structured SGML documents in major Finnish public sector organisations. RASKE was a joint project, whose participants included Parliament of Finland, and ministries of the Finnish government.